

目次
背景
Qiskitについて
量子コンピュータがじわじわと以前に比べて話題に上がりつつあります。その中で、私たちは無料で量子コンピュータの技術や命令手法を学び、試すことができます。そのツールの1つがQiskitです。Qiskitについての概要やハンズオンは以下のリンクを参照ください。
サポートベクターマシン(SVM)による機械学習
サポートベクターマシン(SVM:Support Vector Machine)とは、機械学習分野において、教師あり学習の1種で訓練データと教師データを用いて、データから何らかの分類や回帰予測を導き出すことができる数学的なモデルです。通常のPCで実行するとPythonでは、Scikit-learnというパッケージを用いることで簡単に実装できます。
今回はSVMの説明はこのくらいにして、詳しく知りたい方は以下のリンクなどから見ていただけたら幸いです。
Qiskitの量子機械学習について
Qiskitでは、機械学習のモデルやデータセットが用意されています。例えば、有名なデータセットであるアヤメのデータセットやワインのデータセット。学習モデルだと、SVMやNNなどがあります。基本的に学習モデルやデータセットは関数として与えられ、ドキュメントやソースコードを見ないと仕組みがわからないようになっています。興味がある方は以下のドキュメントから見てみればより深いQiskitの理解につながると思います。
Qiskitを用いた量子機械学習
では早速Qiskitを使って、機械学習をしてみましょう!!!!
今回はSVMのモデルを用いて、アヤメの分類をしていきたいと思います。
実行環境
%qiskit_version_table
パッケージのインストール&インポート
まず、Qiskit Aqua(Algorithms for QUantum computing Applications)を追加でインストールしなければならないため、以下のコマンドをAnaconda環境内で実行します。Aquaは名前の通りアルゴリズムやアプリケーションを提供するパッケージになります。提供するものとして以下のものがあります。
pip install 'qiskit-aqua[cvx]'次に、今回使うパッケージをインポートします。
import numpy as np
from qiskit import BasicAer
from qiskit.circuit.library import ZZFeatureMap
from qiskit.aqua import QuantumInstance, aqua_globals, MissingOptionalLibraryError
from qiskit.aqua.algorithms import QSVM
from qiskit.aqua.components.multiclass_extensions import AllPairs
from qiskit.aqua.utils.dataset_helper import get_feature_dimension
from IPython.display import clear_output
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.decomposition import PCAデータ準備&可視化
アヤメのデータセットをインポートの加工します。今回はqiskit.ml.datasets.irisに少し手を加えたものを定義します。ここではscikit-learnのデータセットに対して、PCAを適応し、次元圧縮しています。
def iris(training_size, test_size, test_ratio, n, plot_data=False):
class_labels = [r'A', r'B', r'C']
data, target = datasets.load_iris(return_X_y=True)
sample_train, sample_test, label_train, label_test = \
train_test_split(data, target, test_size=test_ratio, random_state=42)
std_scale = StandardScaler().fit(sample_train)
sample_train = std_scale.transform(sample_train)
sample_test = std_scale.transform(sample_test)
pca = PCA(n_components=n).fit(sample_train)
sample_train = pca.transform(sample_train)
sample_test = pca.transform(sample_test)
samples = np.append(sample_train, sample_test, axis=0)
minmax_scale = MinMaxScaler((-1, 1)).fit(samples)
sample_train = minmax_scale.transform(sample_train)
sample_test = minmax_scale.transform(sample_test)
training_input = {key: (sample_train[label_train == k, :])[:training_size]
for k, key in enumerate(class_labels)}
test_input = {key: (sample_test[label_test == k, :])[:test_size]
for k, key in enumerate(class_labels)}
if plot_data:
try:
import matplotlib.pyplot as plt
except ImportError as ex:
raise MissingOptionalLibraryError(
libname='Matplotlib',
name='iris',
pip_install='pip install matplotlib') from ex
for k in range(0, 3):
plt.scatter(sample_train[label_train == k, 0][:training_size],
sample_train[label_train == k, 1][:training_size])
plt.title("Iris dataset")
plt.show()
return sample_train, training_input, test_input, class_labels定義した関数を用いて、データセットをインポートします。今回は、2次元にデータを圧縮して、可視化します。
n = 2 # dimension of each data point
sample_Total, training_input, test_input, class_labels = iris(training_size=120,
test_size=30, test_ratio=0.2, n=n, plot_data=True)
print("training_size:"+str(len(training_input["A"])+len(training_input["B"])+len(training_input["C"])))
print("test_size:"+str(len(test_input["A"])+len(test_input["B"])+len(test_input["C"])))
total_array = np.concatenate([test_input[k] for k in test_input])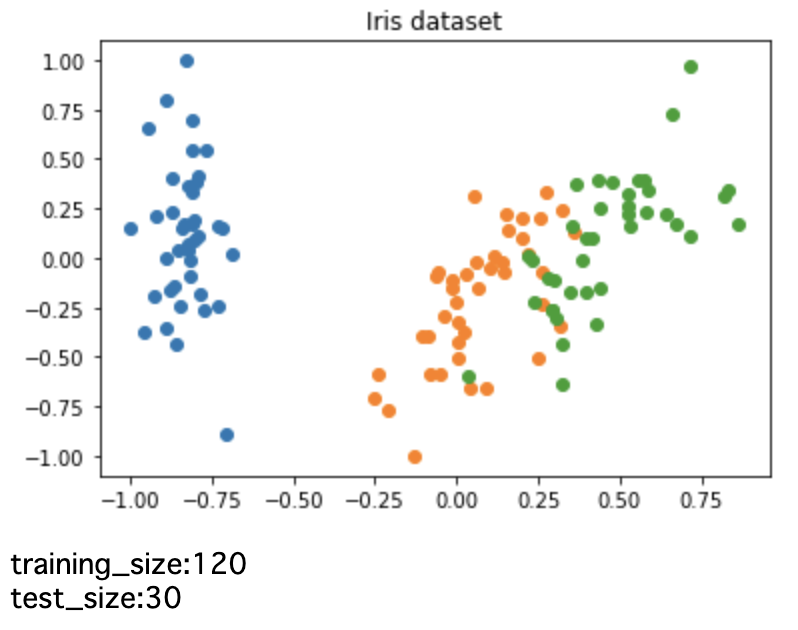
学習
QSVMのインスタンスを作成し、特徴マップを適応して学習を実行します。もつれの変数には線形を選択します。
aqua_globals.random_seed = 10598
backend = BasicAer.get_backend('qasm_simulator')
feature_map = ZZFeatureMap(feature_dimension=get_feature_dimension(training_input),
reps=2, entanglement='linear')
svm = QSVM(feature_map, training_input, test_input, total_array,
multiclass_extension=AllPairs())
quantum_instance = QuantumInstance(backend, shots=1024,
seed_simulator=aqua_globals.random_seed,
seed_transpiler=aqua_globals.random_seed)
result = svm.run(quantum_instance)結果
結果はresultの変数の中で辞書型で格納されているので、以下のコードで表示します。
for k,v in result.items():
print(f'{k} : {v}')
まとめ
Qiskitによる量子機械学習の体験はいかがでしたか?今回は、仕組みについては言及せずにプログラミングを通して、量子機械学習について触れました。量子コンピューティングについて知っていく上で、まずは触ってみることは、1つのステップとして重要だと思っており、これを読み切り実装しきった方はそれを達成されたのかなと思っています。
これからもみなさんと一緒に量子コンピューティングについて勉強していけましたら幸いです。
参考文献
https://qiskit.org/documentation/stable/0.24/locale/ja_JP/_modules/qiskit/ml/datasets/iris.html
https://github.com/Qiskit/qiskit-aqua
https://blueqat.com/tetsurotabata/11e287c2-7723-4f7e-b18a-bcdff39d50b7
